How to Quantize Large Language Models - Super Lazy Coder
Super Lazy Coder Tutorial Summary
Table of Contents
- Quantization Technique for Large Language Models | 0:00:00-0:14:00
- Using GPTQ Technique for Model Quantization | 0:14:00-0:25:00
- Quantizing Models with Llama CPP Library | 0:25:00-10:10:10
Quantization Technique for Large Language Models | 0:00:00-0:14:00
https://youtu.be/q8LUnvPwiSA?t=0
The source for this section can be found here: Introduction to Weight Quantization
In this video, we discuss the quantization technique of large language models. Quantization is the process of reducing the size and computational requirements of a model by converting its parameters into lower precision data types. The number of parameters in a model determines its size and computational requirements. Loading a model with a large number of parameters requires more memory. The precision of the parameters is determined by the data type, such as float 32 bit. The weight of the parameters is the total number of bits required to store the model in memory. You are asking if each parameter in the model uses a certain number of bits.
Quantization is a technique used to reduce the size of large language models so they can be used on smaller machines. There are two major quantization techniques: post training and quantization aware training.
Post training involves compressing a pre-trained model, while quantization aware training involves compressing a model during training. The GPTQ technique is a popular quantization technique that converts parameters into smaller bit precision sizes. It is useful for GPUs with limited memory. GPTQ uses optimal weight quantization to compress weights while minimizing the difference between the old and compressed weights. Layer-wise compression is also used in GPTQ. Overall, quantization reduces the size of language models, making them more accessible for smaller machines.

The large language model, Gemma, is based on the transformers architecture. It takes an input and goes through multiple layers, including embedding, attention, normalization, and feed forward layers. The output is generated using the same process but in reverse. Each layer has 7 billion parameters that need to be trained. Optimal brain quantizer is used to compress the weights at each layer. GPTQ uses three techniques to make the compression process faster: arbitrary order insights, lazy batch update, and weight sharing.



Using GPTQ Technique for Model Quantization | 0:14:00-0:25:00
https://youtu.be/q8LUnvPwiSA?t=460
The source for this section can be found here: 4-Bit Quantization with GPTQ
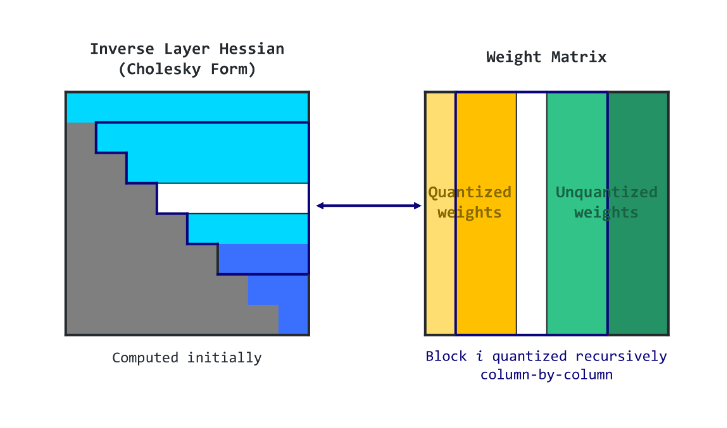
GPTQ uses a lazy batch update to transform weights in batches, making the process faster. It also uses the Cholesky reformulation to reduce numerical errors. To quantize a model, you need to install the auto gptq library and import the necessary modules from transformers.


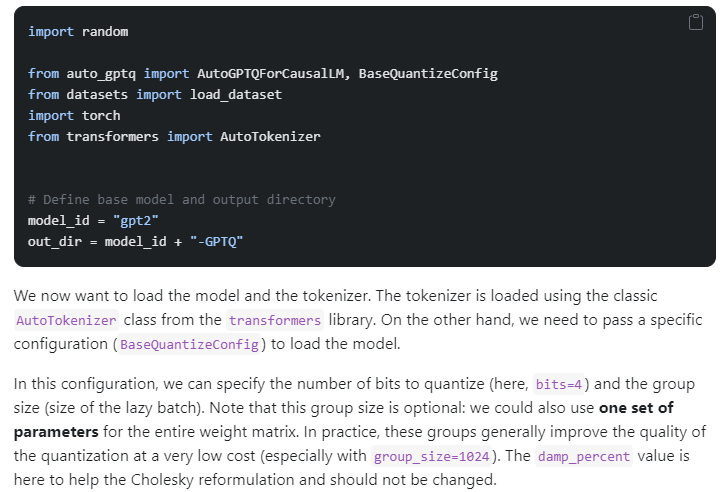
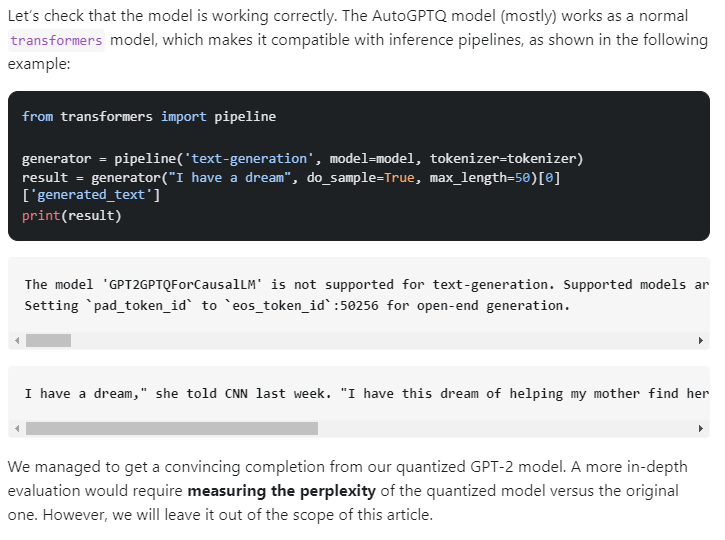
To use the GPTQ technique, you need the auto tokenizer and GPTQ config. The tokenizer provides the embeddings for the model. Load the pre-trained tokenizer and create the GPTQ config with the desired parameters. Use a dataset like C4 to train the model for quantization. Load the auto model for casual LM with the model ID and GPTQ config to quantize the model. Push the quantized model to the Hugging Face hub. GPTQ only works on GPUs.


Quantizing Models with Llama CPP Library | 0:25:00-10:10:10
https://youtu.be/q8LUnvPwiSA?t=1500
The source for this section can be found here: # Quantize Llama models with GGUF and llama.cpp

The steps here
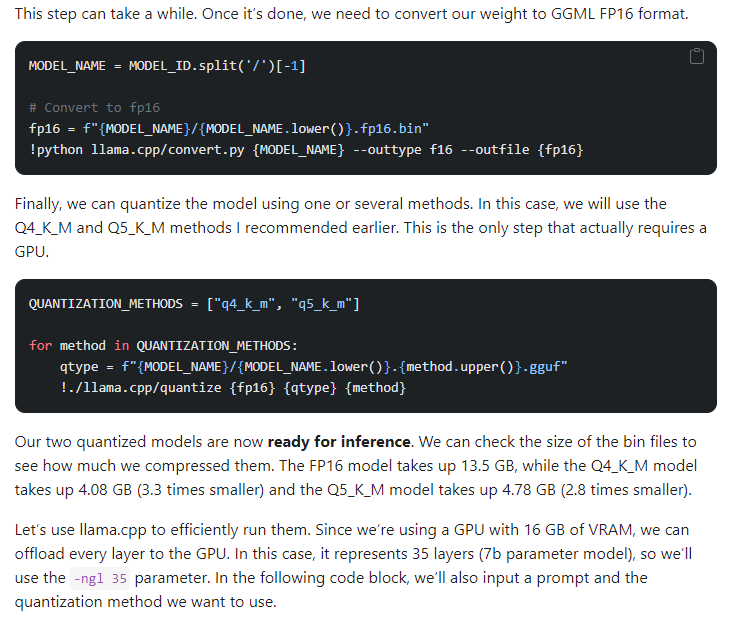
To run on CPUs, use the GGUF technique. GGUF uses the ggml library, which is compatible with the Llama CPP library. GGUF allows running models on both GPUs and CPUs. Quantize llama models with GGML using different variations, such as Q2K or Q80, depending on the desired precision. Attention and feed forward layers are important and should not be compromised during weight compression.
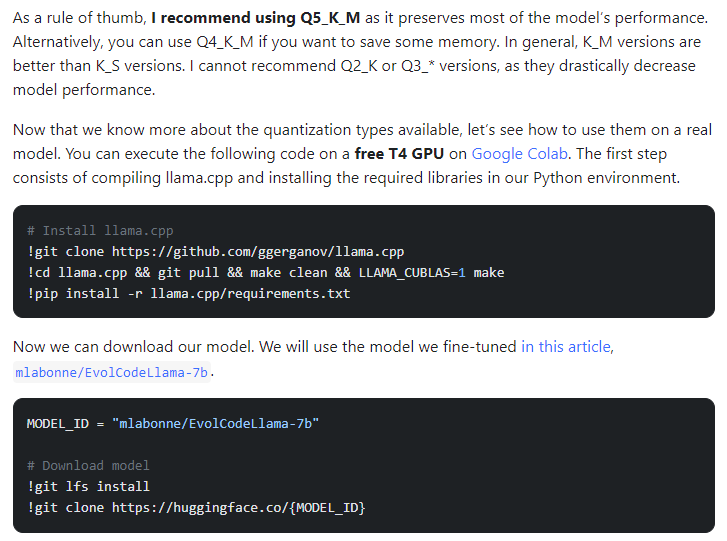
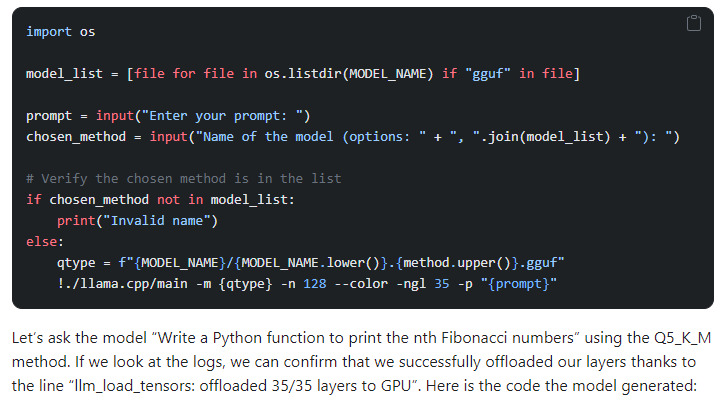
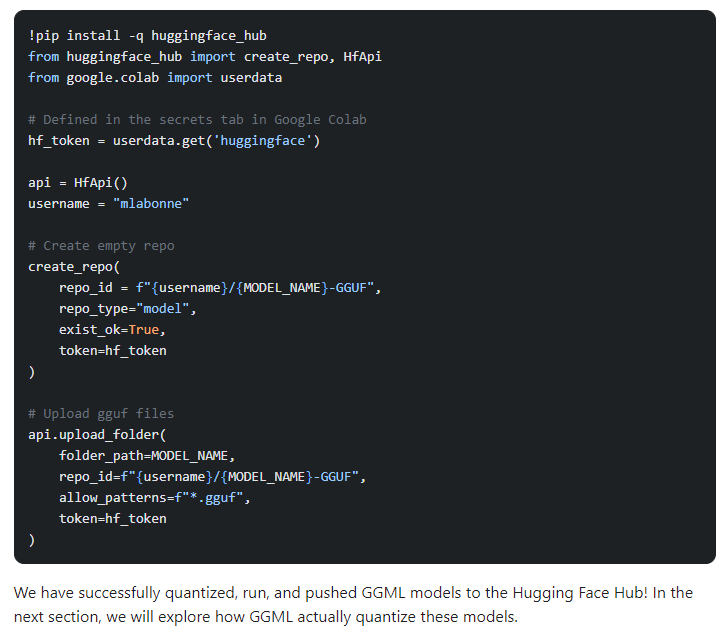
Steps: 1) quantize models by cloning the library, 2) install prerequisites, 3) and convert the model to a 16-bit GGML format. They perform quantization using different methods and create models in the GGUF format. Finally, load and use the quantized models using the Llama CPP Python library. The two popular approaches to quantization are GGML and GPDQ.