Mixtral of Experts (Paper Explained) - Yannic Kilcher
Yannic Kilcher Summary

Table of Contents
Introduction to Mixtral 8x7b Mixtro of Experts Model | 0:00:00 - 0:01:40
https://youtu.be/mwO6v4BlgZQ?t=0
I believe that using synthetic data is a smart choice due to the current trend among professional complainers to criticize the source of training data, leading to lawsuits over copyright issues. Previously, complaints focused on model biases and crowd workers.
Importance of Transparency in Research Papers | 0:01:40 - 0:03:00
https://youtu.be/mwO6v4BlgZQ?t=100
This paper doesn't hold many surprises. It states that the model is a transformer with a mixture of experts architecture, providing an opportunity to understand its meaning. I've made videos about the mixture of experts and expert routing in the past, but it's worth delving into the topic again here.

Introduction to Mixtral 8x7b | 0:03:00 - 0:07:20
https://youtu.be/mwO6v4BlgZQ?t=180
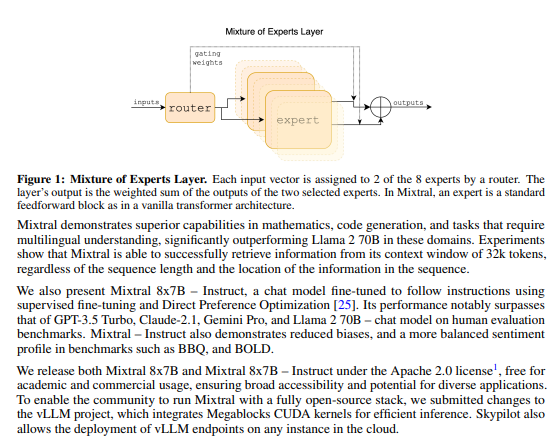
The total parameter count of the model is less than other models like GPT-3.5 and GPT-3, although the exact number is not specified. The model utilizes a mixture of experts with expert routing, allowing it to use only a subset of parameters for each token. This results in a lower actual parameter count per token, contributing to its performance on various benchmarks.
The model allows for optimizations to achieve faster inference speed at low batch sizes and higher throughput at large batch sizes. It is a decoder-only model with feedforward blocks that select from eight distinct groups of parameters. This selection process will be further explored to understand its significance.
There's a context size, or token window, of 32,000, which is comparable to other large, transformer-based language models. This window is substantial, providing a significant context. Our first indication of where the training data originates is it pre-training with multilingual data. Thus, they could literally use a pile of multilingual data, such as a piece by Shakespeare with an added German phrase. However, the specifics aren't divulged.
So, what is a mixture of experts model? Commonly in transformers, we frequently discuss attention, the attention mechanism, which has traditionally been the central component of these transformer models. Essentially, transformer models involve turning your input tokens into a vector, performed by an embedding layer. Consequently, at the top, there is an output akin to a reversed embedding layer, also known as negative one embedding. The output vectors are then converted back into tokens, or if predicting the next token, one at the very end is predicted into one of the 32,000 tokens or thereabouts.
In between, there are transformer blocks, repeated 'n' times. Over the years, these transformer blocks have evolved somewhat but typically consist of two primary layers - the attention layer and the feedforward layer. Hence, there is usually an attention layer followed by a feedforward network or layer. Notably, when discussing transformers, the attention layer is typically the centre of discussion.
Attention Layer in Neural Network | 0:07:20 - 0:12:20
https://youtu.be/mwO6v4BlgZQ?t=440
Sparse Mixture of Experts Model and Routing Neural Network | 0:12:20 - 0:21:20
https://youtu.be/mwO6v4BlgZQ?t=740

After applying softmax to logit, a distribution or weighting is obtained. This is used to route input to different experts for signal gathering. The routing is based on weightings determined by a function. Each token goes through the same process with different weightings. The routing and computation path vary for each signal. The process involves routing network, expert network, and weighted sum based on routing and expert output. Sparse output from routing function reduces computation by focusing on relevant experts. This approach reduces parameter count and assigns different experts to different tokens. There is no entropy regularization to ensure tokens are routed to different experts, but it may have been used in previous papers. Overall, the process optimizes computation and expert usage without the need for additional constraints.
The other thing here, so they say, E_i denotes the output of the i-th expert. So i are the number of experts and they go to n, I guess, there are n experts. And then here gx sub i denotes the n-dimensional output of the gating network for the i-th expert.

This, I believe, is a mistake in the the paper? Maybe not, but so if you think of it, if like this thing here outputs a vector, right? And you ultimately sum these vectors and you want another vector, then these things here, they must either be scalars or matrices, but they cannot be like n-dimensional.
The output of the gating network for the i-th expert cannot be n-dimensional. So I believe what they meant to say is that g of x has an n-dimensional output and then gx of sub i is the i-th entry of that n-dimensional output, which this n-dimensional output is just that what I said before this kind of classification layer where you only take the top k, in their case the top two entries before so you set everything else to zero and then you normalize that using a softmax.
So the neural network is just a linear feed forward layer so there is a function ff, let's call it ff, and we apply it to each token individually, which means that every single token goes through the same function in here. And that function is always the same function. So that hasn't changed. What has changed is that internally, inside of these functions, if you peer in, then an input x might take a different path than an input y. So the input y might take a different computation path in here and activate different parameters inside of this. But it's still the case that each token is pushed separately through that feedforward stage. It's just that inside of that feedforward stage, we have some sparse elements and depending on the signal that we put in there, depending on the token, it gets routed differently.
Routing and Expert Parallelism for High Throughput Processing (SparseNet) | 0:21:20 - 0:27:20
https://youtu.be/mwO6v4BlgZQ?t=1280

SparseNet involves routing tokens to different experts on GPUs to increase throughput. By using a sparse mixture of experts, the model can achieve higher throughput by distributing tokens efficiently. The speaker explains that the magic of machine learning lies in this new feed-forward layer with routing and softmax aggregation. Experimental results show that SparseNet outperforms models like LLama 270 billion and GPT-3.5. However, be cautious about interpreting plots comparing active parameters in different models because of the dynamic selection of active parameters in SparseNet. The model performs well in tasks like reasoning and retrieval, demonstrating its ability to retrieve information from context windows effectively. Smartly selecting what to include in the context is more effective than adding everything.
Impact of Selective Information Inclusion | 0:27:20 - 0:31:20
https://youtu.be/mwO6v4BlgZQ?t=1640
Routing Analysis: Experts Assigned Consecutive Tokens | 0:31:40 -
https://youtu.be/mwO6v4BlgZQ?t=1880

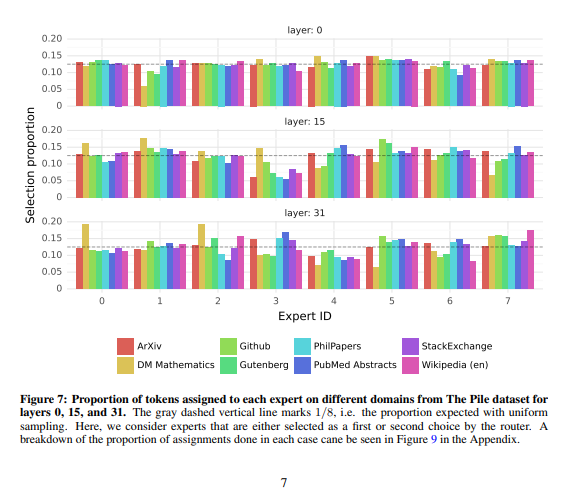
The patterns may be complex or beyond human understanding, but there is the possibility of finding regularities in the future and it is important to research this to build new applications. I praise the release of the analysis on Apache for wider accessibility. I can only speculate on the reasons for keeping the data source undisclosed, but I'm excited about the potential of open source AI applications like Mixtrel.
