But what is a GPT? Visual intro to Transformers - 3Blue1Brown
3Blue1Brown Visualizations
Table of Contents
- Understanding GPT: Generative Pre-trained Transformer | 0:00:00-0:06:00
- Details of Transformer Network Structure and Training | 0:06:00-0:10:00
- Model Parameters/Weights in Deep Learning | 0:10:00-0:12:40
- Word Embedding Vectors: Semantic Meaning and Geometry | 0:12:40-0:18:00
- Vectors in Transformer Embedding Space | 0:18:00-
https://youtu.be/wjZofJX0v4M
Editors Note: This content is more about an introduction to deep learning than a deep dive into attention mechanisms.
Understanding GPT: Generative Pre-trained Transformer | 0:00:00-0:06:00
The initials GPT stand for Generative Pre-trained Transformer. The first term, "Generative," refers to bots that create new text. The term "Pre-trained" refers to the model's process of learning from a massive dataset, suggesting that additional training can fine-tune it for specific tasks. The last term, "Transformer," refers to a specific type of neural network and machine learning model that is crucial for the current AI development.
The intention of this video and subsequent chapters is to give a visually driven explanation of what happens inside a transformer. We will follow the data flowing through it step by step. Many different models can be built using transformers. Some models can transcribe audio, while others can generate synthetic speech from text. Tools like Dolly and Mid-Dragon, which takes in text and produce images, are based on transformers. They are impressive, even if they cannot perfectly comprehend the concept of a pie creature.
The transformer was first introduced by Google in 2017, specifically for translating text from one language to another. However, the version that we will concentrate on underlies tools like ChatGPT. It's trained to read a piece of text—possibly accompanied by images or sounds—and predict what comes next. This prediction is in the form of a probability distribution over possible subsequent text fragments.
At first glance, predicting the next word may seem different from generating new text. But once you have a prediction model like this, you can generate a longer text by using an initial fragment, selecting a random sample from the generated distribution, and continuously predicting based on the new text. The process might not seem plausible, but it works.
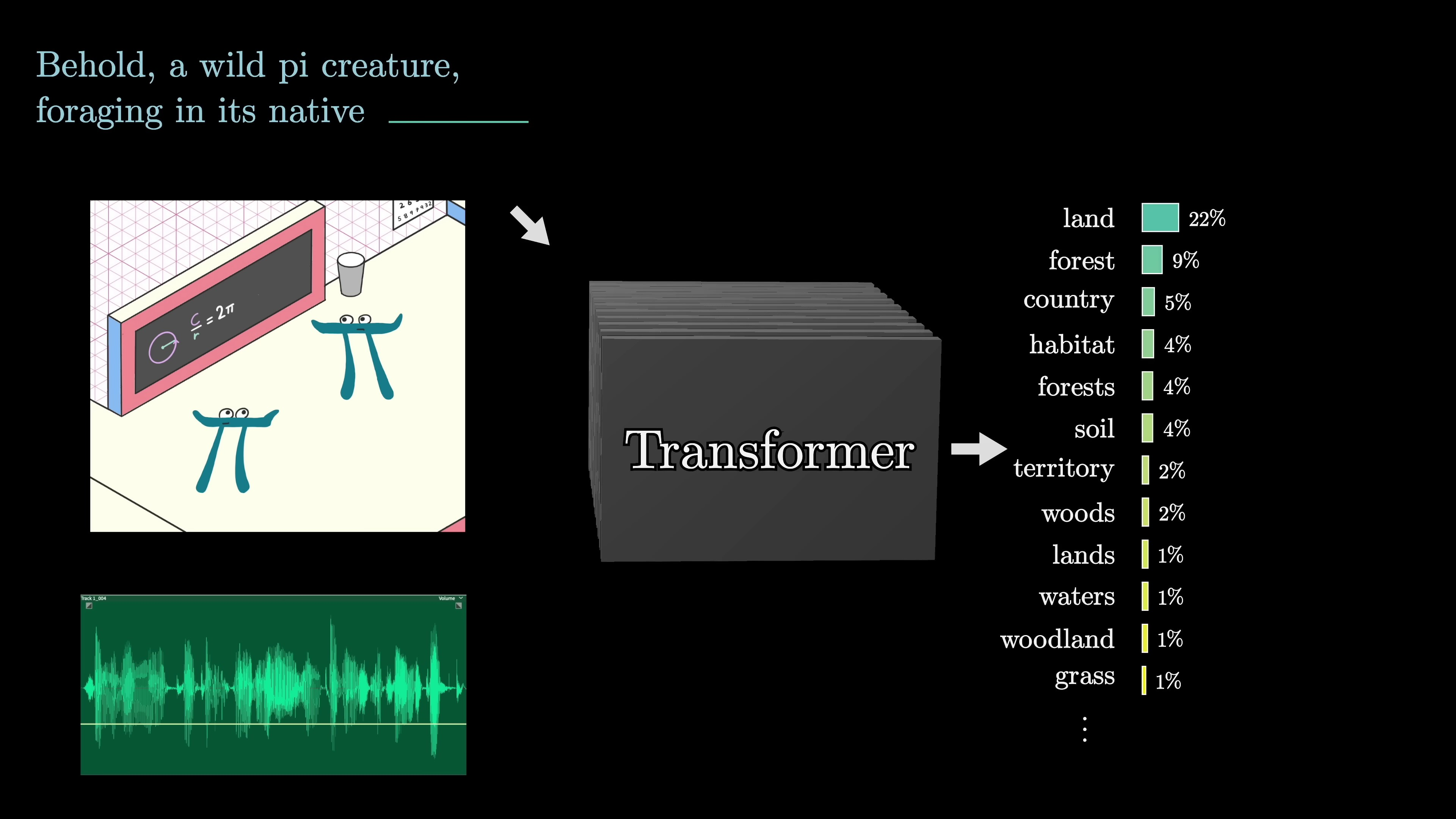
For instance, an animation running GPT-2 will generate text based on a given seed phrase. If we exchanged the GPT-2 for GPT-3, a larger version of the model, we get a coherent story. The repeated process of predicting and sampling is essentially what happens when you interact with chatbots like ChatGPT.
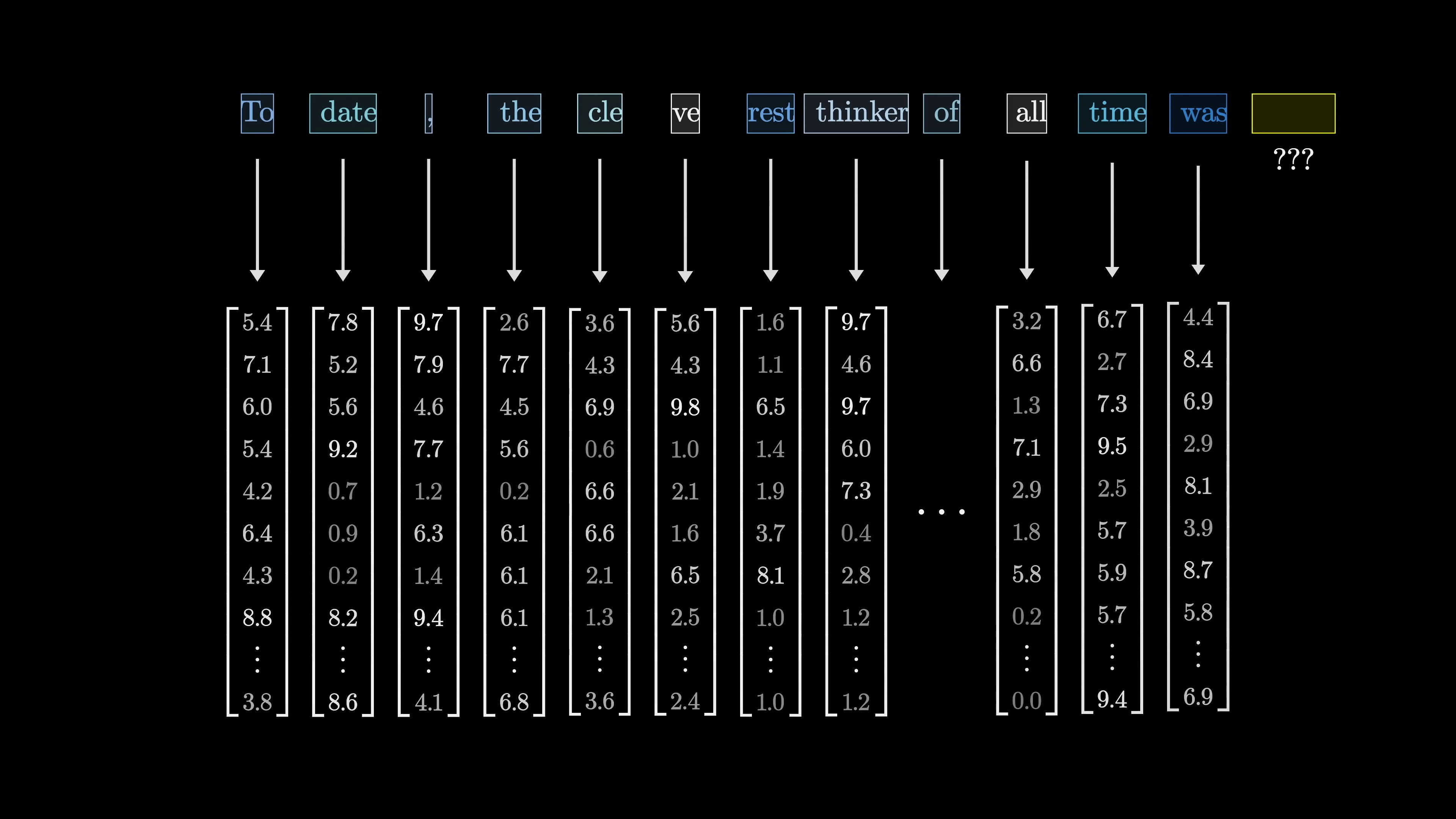
Now let's provide a high-level overview of how data flows through a transformer. When a chatbot generates a word, here's what's happening under the covers. The input text is divided into tiny pieces called "tokens," usually words, fragments of words, or other character groups.

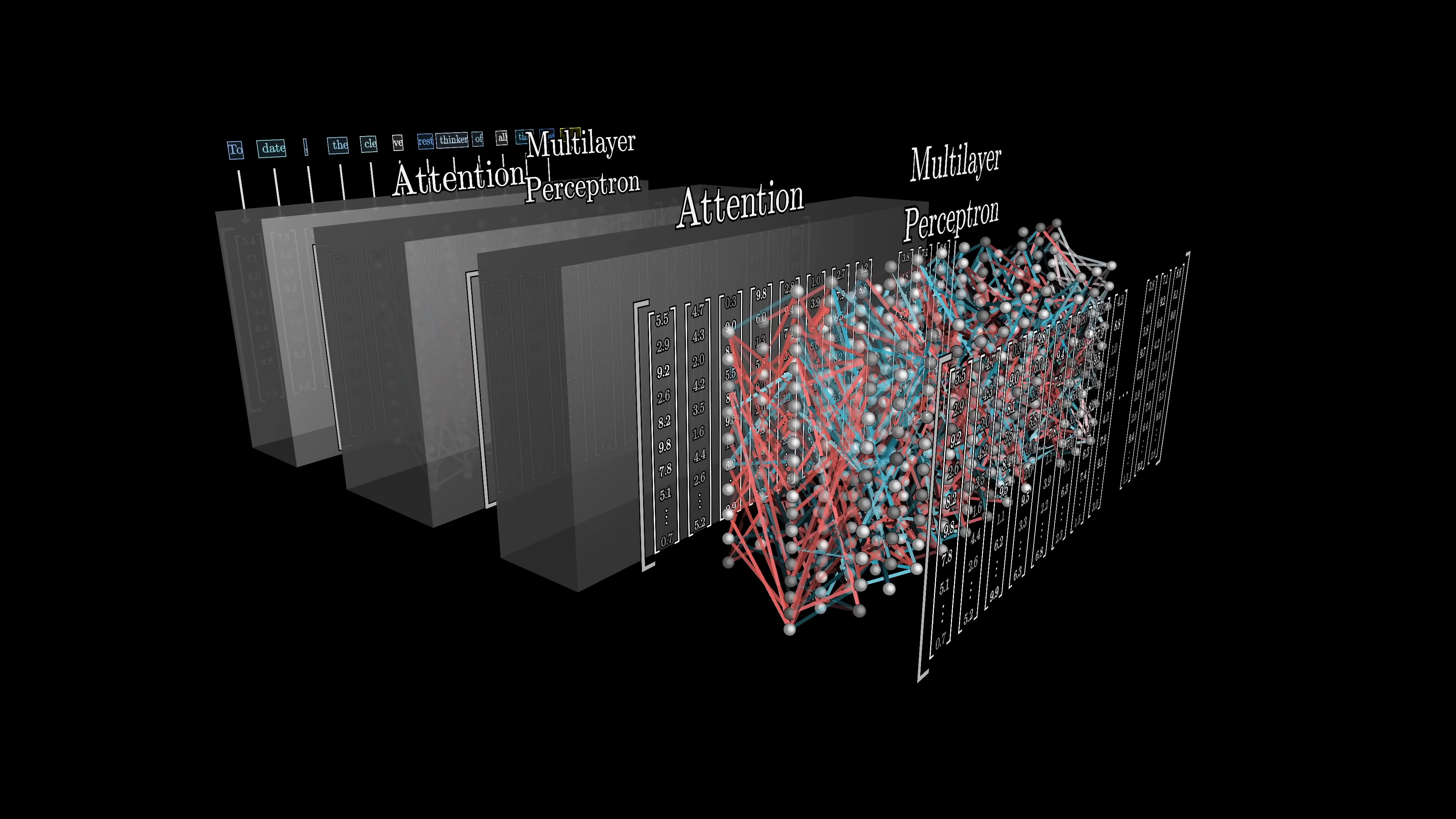
In natural language processing, tokens representing text or sound correspond with vectors that encode their meanings in a high-dimensional space. Words with similar meanings have neighboring vectors. An attention block allows vectors to interact and update their values based on context. Then, a multi-layer perceptron or a feed-forward layer processes the vectors parallelly. This step involves questioning each vector and updating them based on the responses.
The cycle of attention blocks and multi-layer perceptron blocks repeats, capturing the passage's meaning in the final vector. This vector generates a probability distribution over potential subsequent tokens.
Deep Learning Fundamentals | 0:06:00-0:10:00
https://youtu.be/wjZofJX0v4M?t=360
There's an added training step required to optimize this process, which we'll discuss at length later. For now, we'll focus on the initial stages of the network, the final stages, and reviewing some vital background knowledge. This knowledge would have been second nature to any machine learning engineer by the time transformers were introduced. But before delving into the Transformer specifically, it's crucial to understand the basic premise and structure of deep learning.
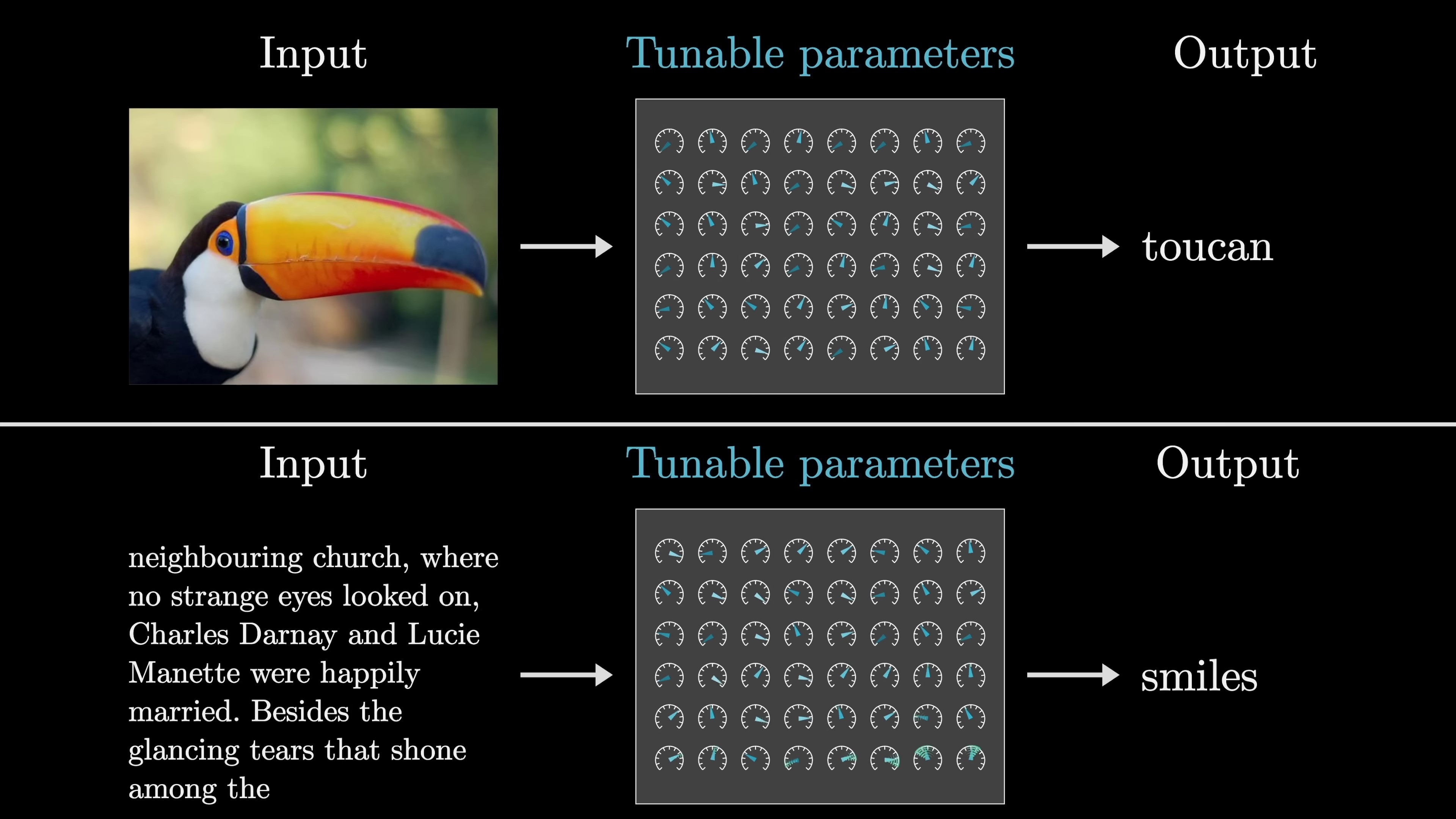
At the risk of oversimplifying, this is one approach to machine learning, which refers to any model where data is used to determine a model's behavior. Let's say, for instance, you want a function that takes an image as input and outputs a descriptive label, or our example of predicting the next word from a given text passage. This requires pattern recognition and a degree of intuition.
In the early days of AI, people would explicitly define a procedure for such tasks in code. Contrastingly, the modern approach involves setting up a flexible structure with adjustable parameters. Using numerous examples of what the output should look like for a given input, these parameters can be tweaked to replicate this behavior.
Perhaps the simplest form of machine learning is linear regression, where the inputs and outputs are single numbers, such as the square footage of a house and its price. The objective is to find a line of best fit through this data to predict future house prices.
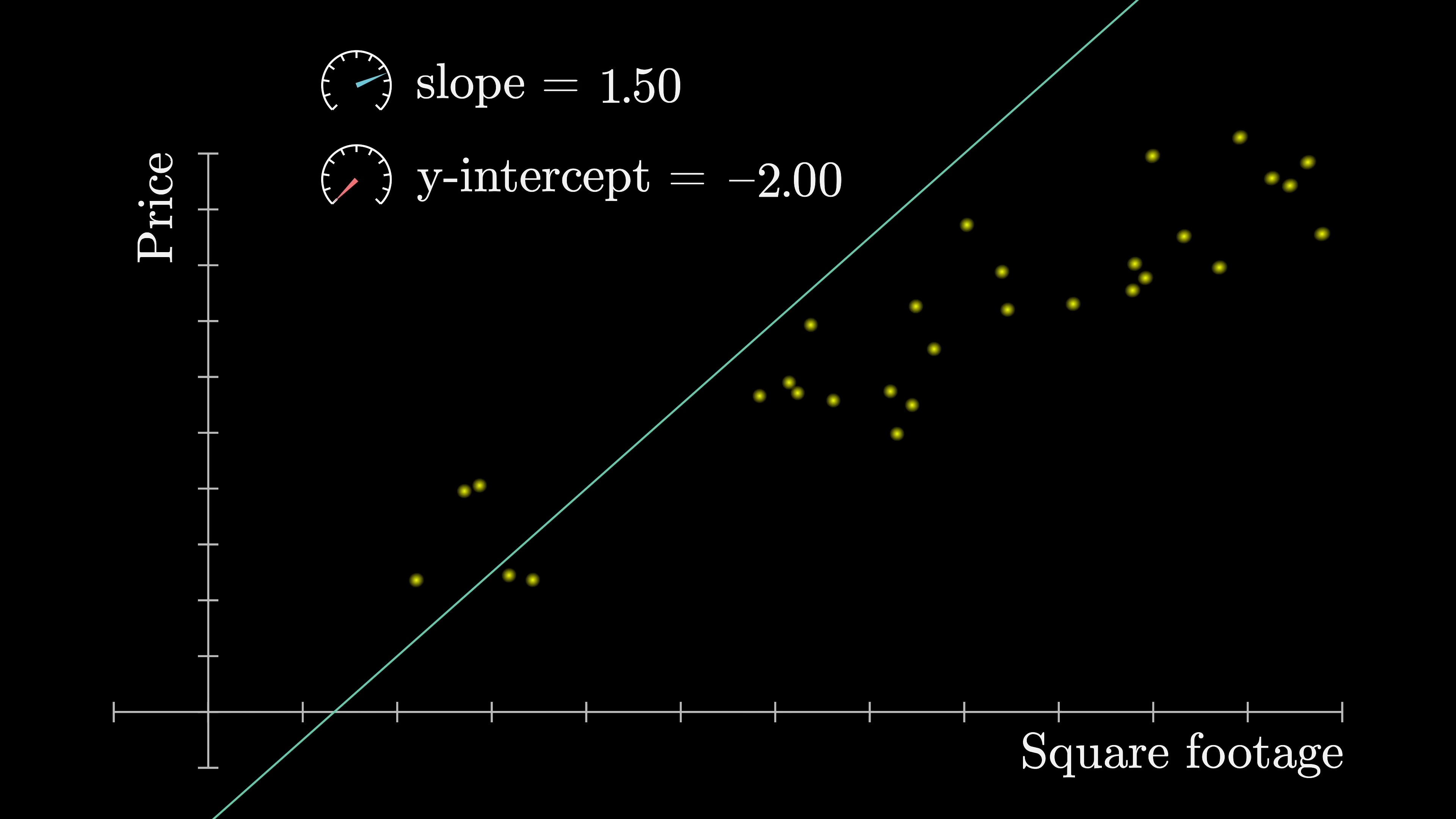
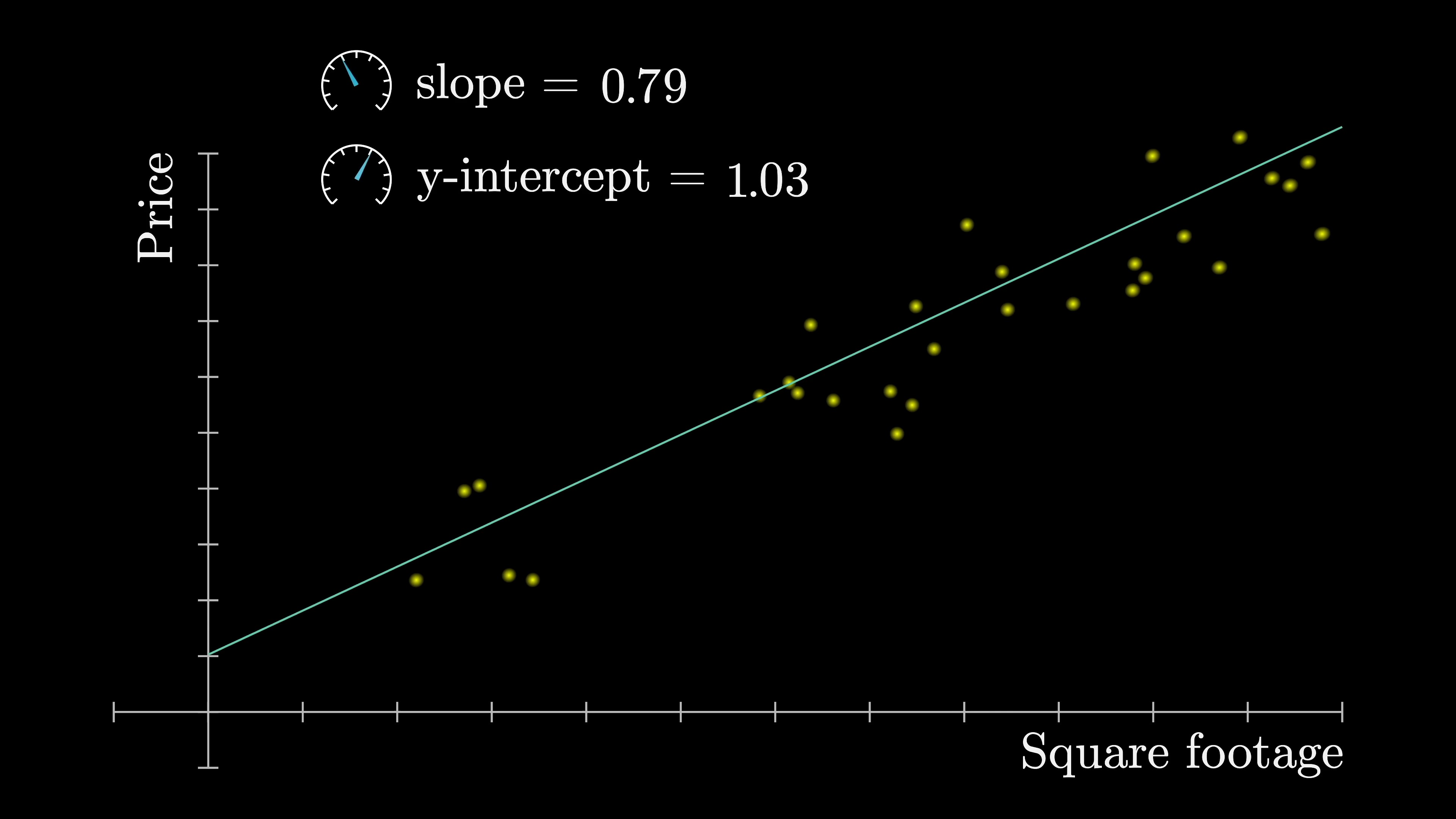
Deep learning models are much more complex. For example, GPT-3 has not two, but 175 billion parameters. Remarkably, deep learning models have proven to scale astonishingly well over the last couple of decades, provided they adhere to a specific format.
Model Parameters/Weights in Deep Learning | 0:10:00-0:12:40
https://youtu.be/wjZofJX0v4M?t=600
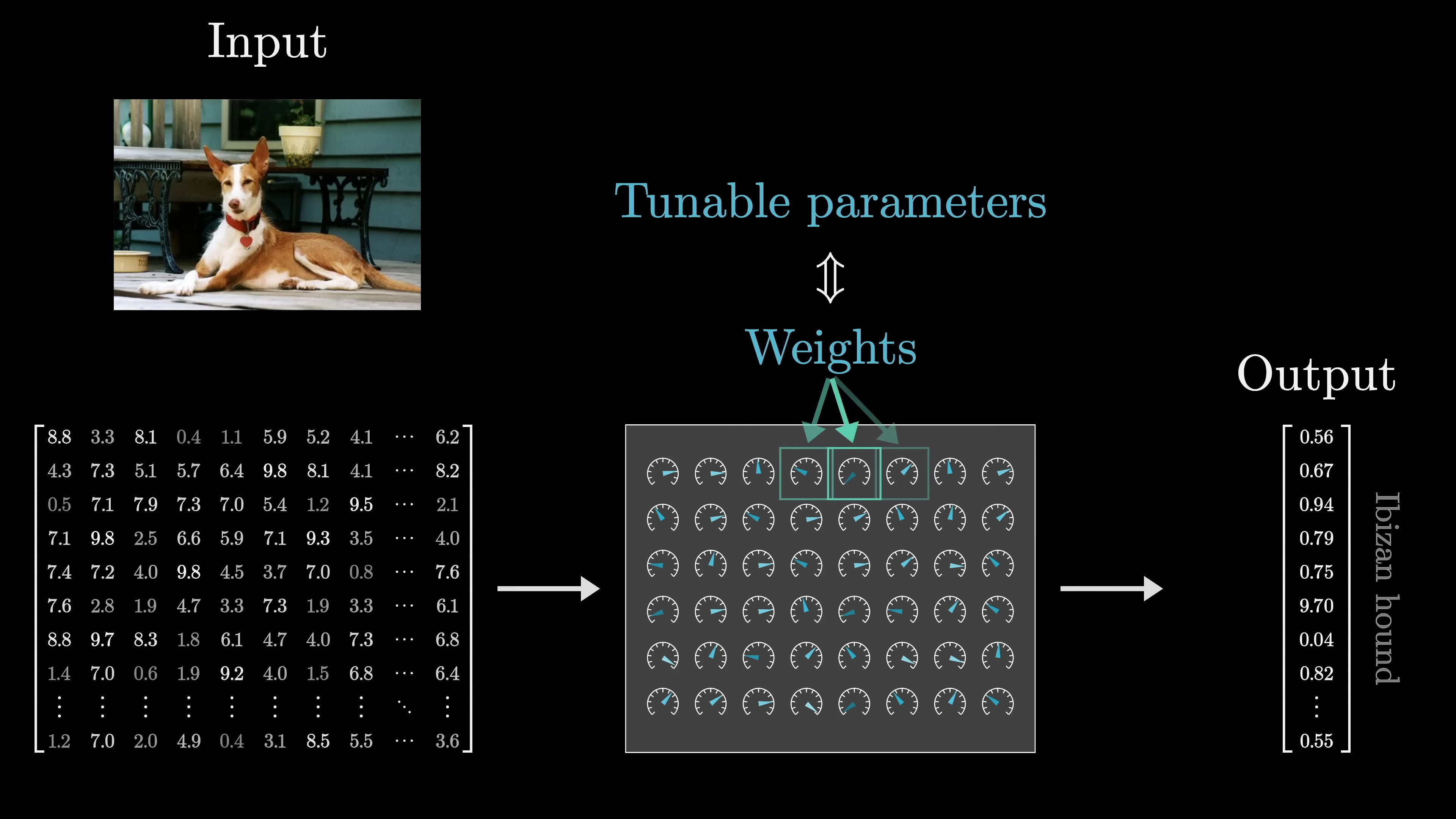
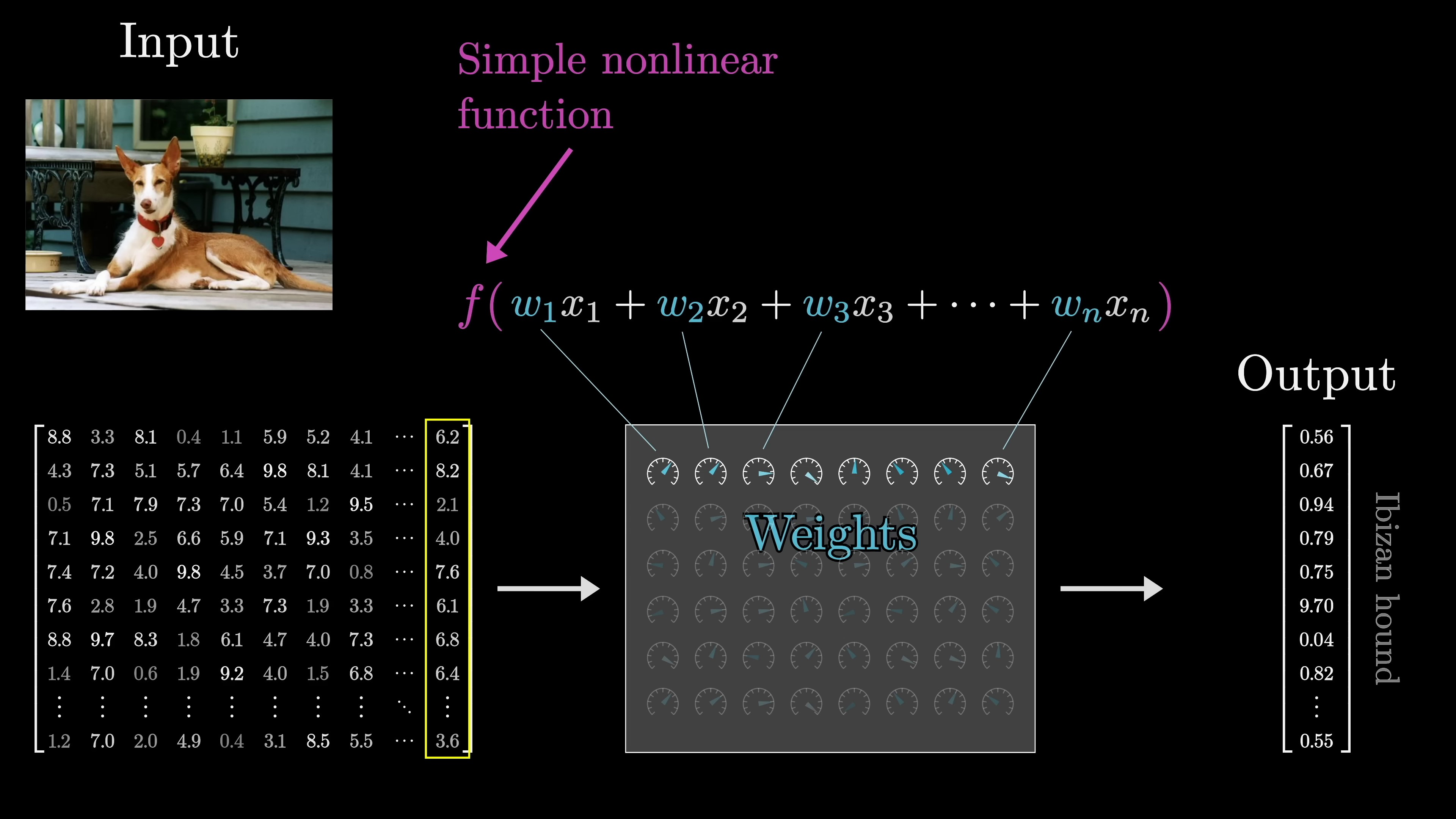
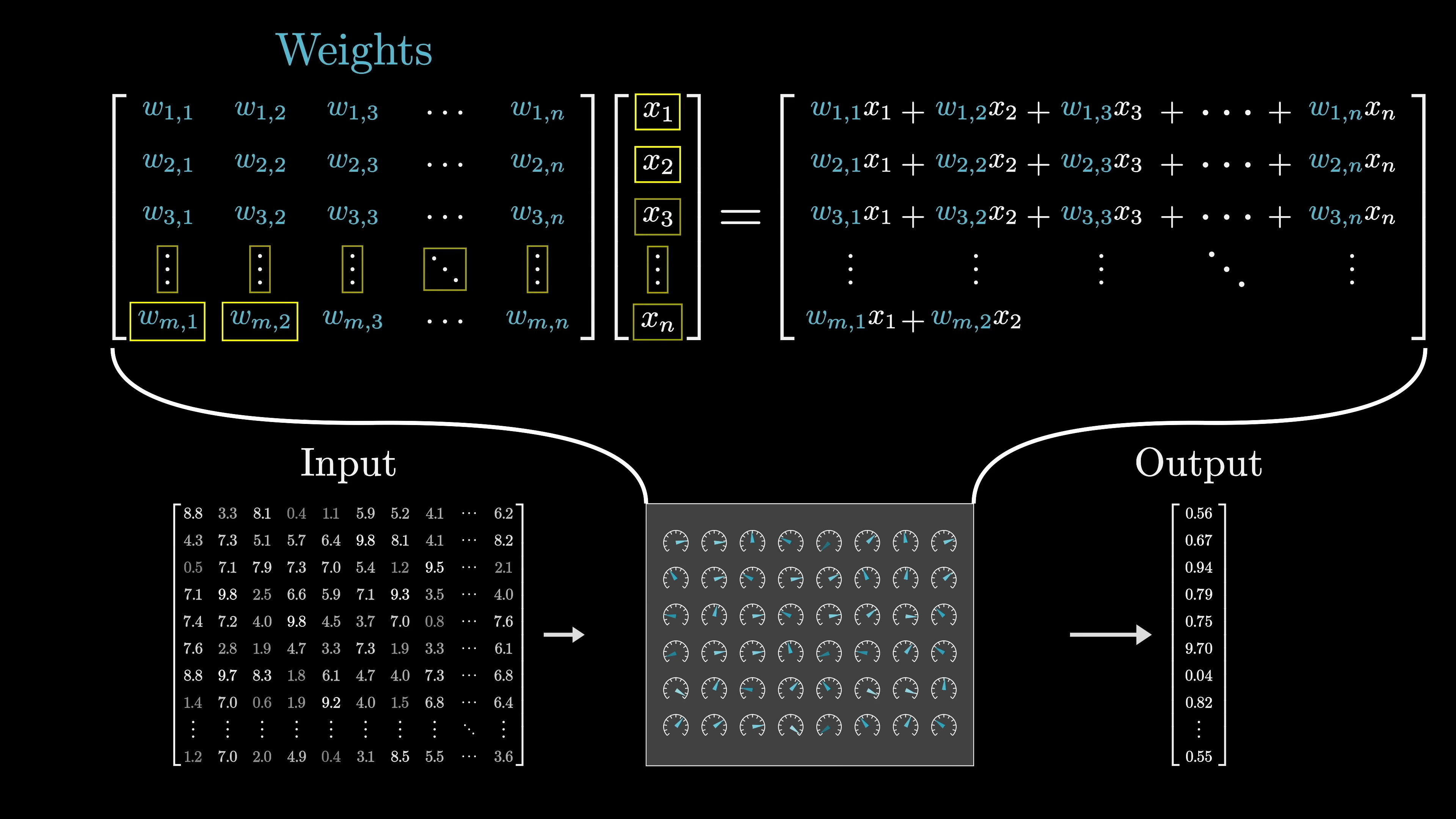
The key training these models is to format the input as an array of real numbers, which could be a list of numbers, a two-dimensional array, or even higher-dimensional arrays, collectively termed "tensors". This input data is transformed progressively into various distinct layers, structured as an array of real numbers, leading to a final layer which is considered the output. In the case of our text processing model, the final layer is a list of numbers representing the probability distribution for all possible subsequent tokens.

In deep learning, model parameters are referred to as weights because they interact with data through weighted sums. Nonlinear functions are also used but do not depend on parameters. These weighted sums are often represented as matrices and vectors for cleaner conceptualization. For example, GPT-3 has 175 billion weights organized into 28,000 matrices across 8 categories. Exploring these categories helps understand the model's functionality. Despite newer models, GPT-3 remains notable for its impact. Modern networks keep specific numbers confidential. Matrix-vector multiplication is a key computation in models like ChatGPT, with a distinction between model weights (colored blue or red) and data (colored gray).


Word Embedding Vectors: Semantic Meaning and Geometry | 0:12:40-0:18:00
https://youtu.be/wjZofJX0v4M?t=760
Weights in a model represent the knowledge gained during training and dictate its behavior. Data processed by the model encodes specific inputs, like text snippets. The first step in text processing involves breaking the input into tokens, which are converted into vectors. Tokens can be fragments of words or punctuation.

However, it is convenient to visualize embeddings as words. Each word in the list corresponds to a column in the matrix, which determines the vector representation of the word. The values in the matrix are initially random but are learned from data. This process of turning words into vectors predates transformers and forms the basis for subsequent machine learning techniques.

The embedding of a word is often referred to as a word vector, which encourages thinking of these vectors in a geometric sense as points in a high-dimensional space.
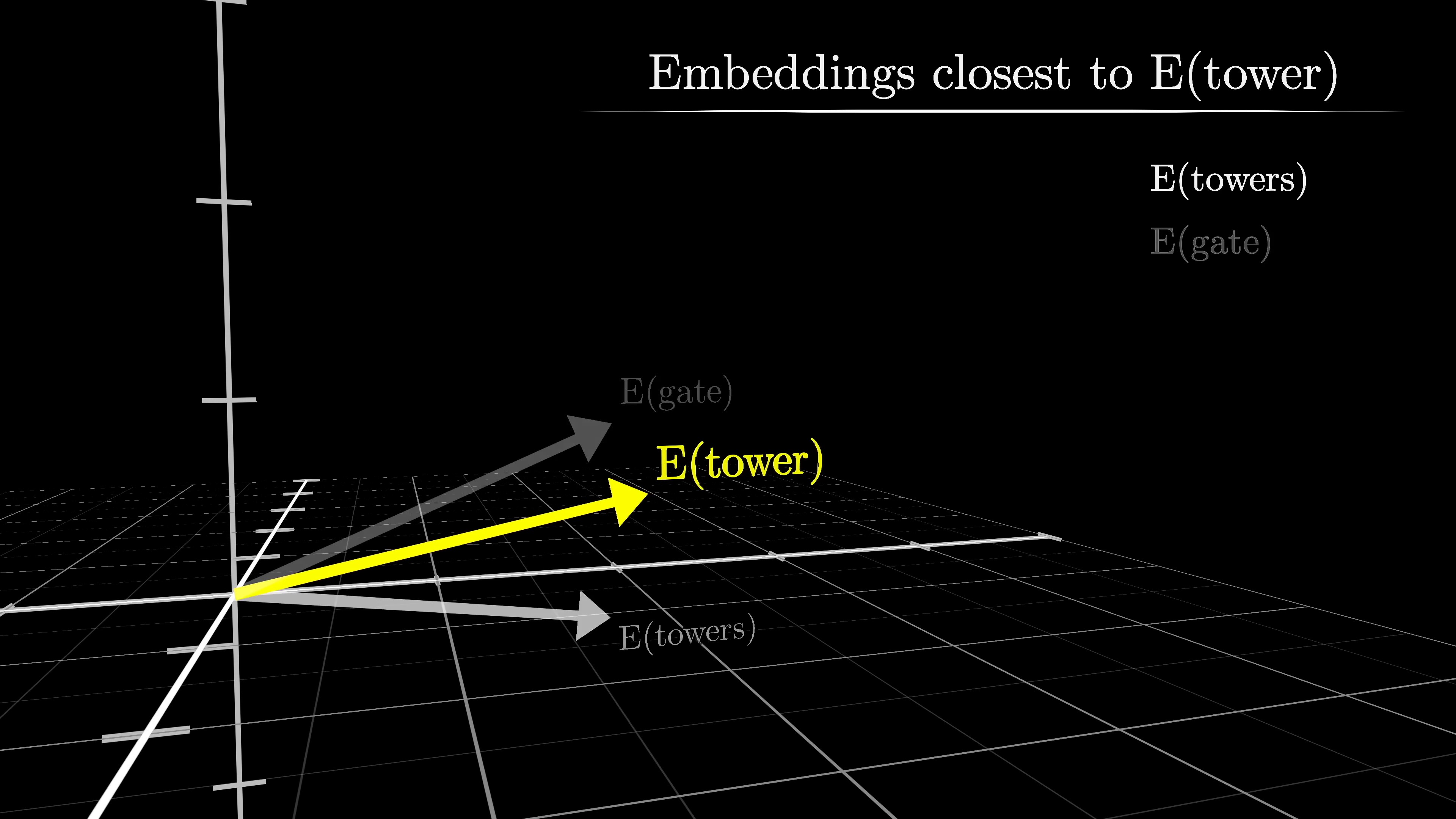
Word embeddings in GPT-3 are high-dimensional, with 12,288 dimensions. To visualize them, a 3-dimensional slice is chosen to project the word vectors onto. This allows for displaying the embeddings in a more manageable space. The model tunes its weights during training to embed words as vectors, where directions in the space have semantic meanings. By finding words closest to a specific word like 'tower', similar semantic vibes can be observed. The process involves running a simple word-to-vector model and projecting the embeddings onto a 3D space for visualization.

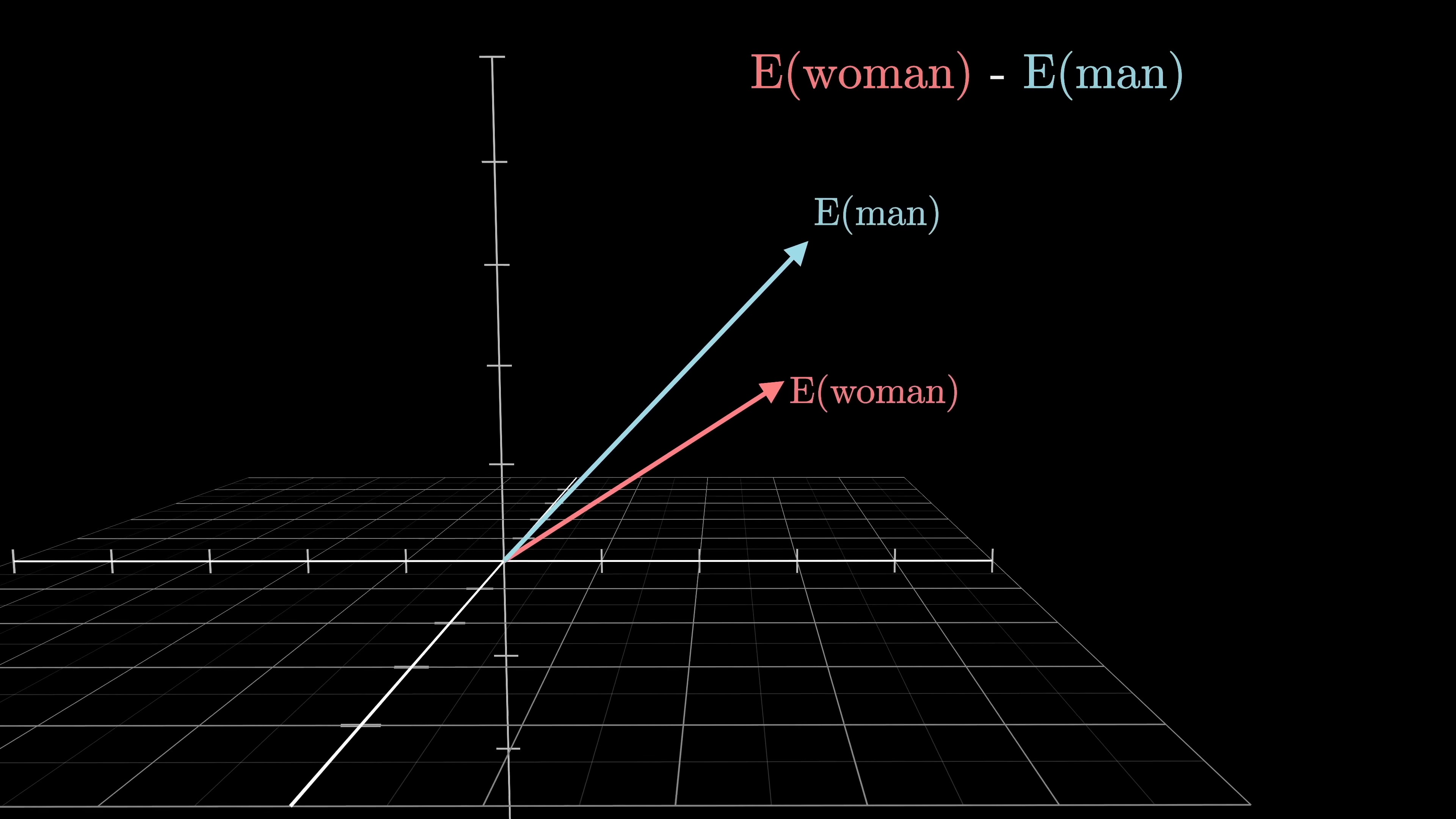
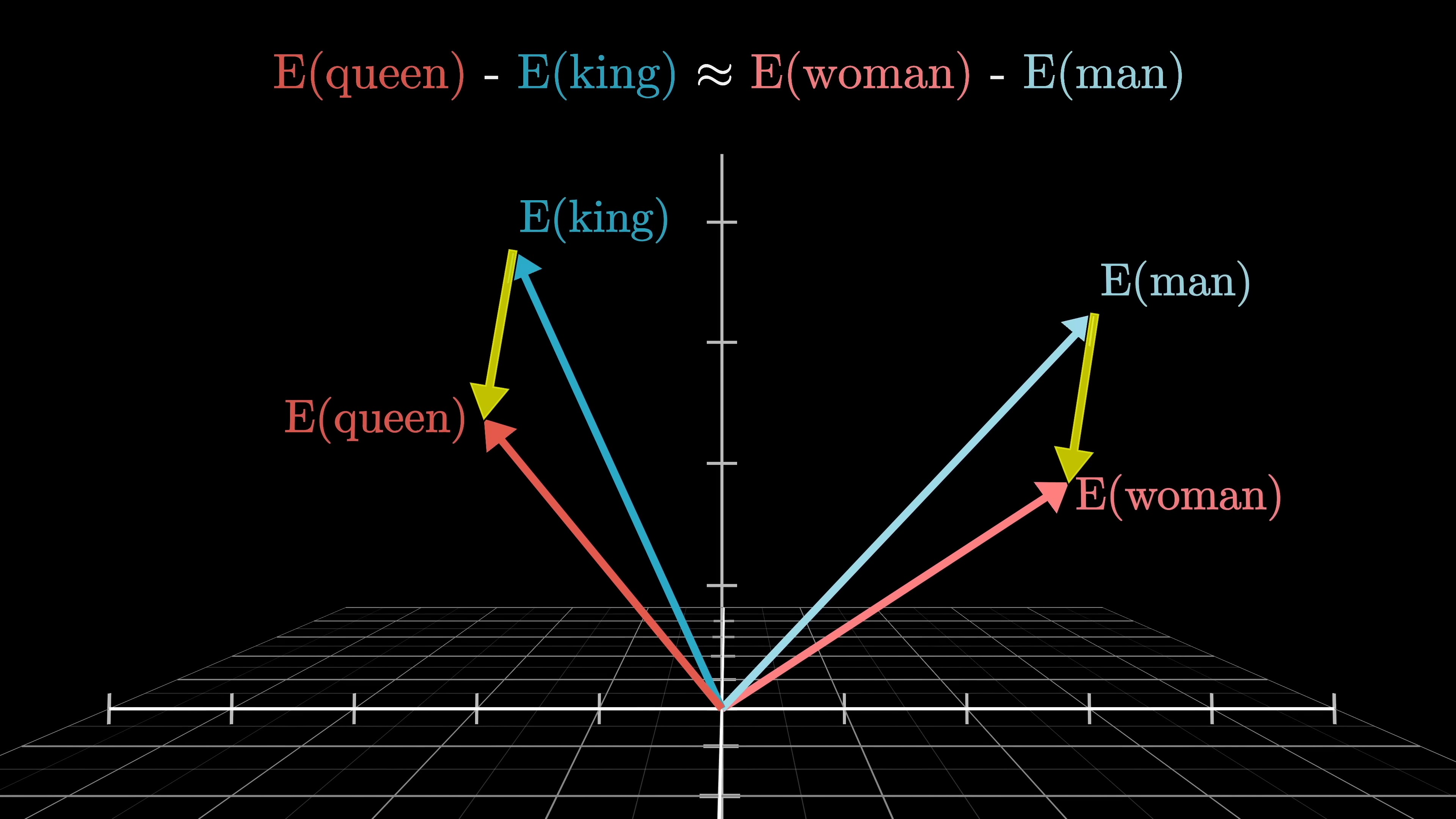
The concept of semantic meaning in vector spaces is illustrated by the relationships between word embeddings. For example, the difference between vectors for 'woman' and 'man' is similar to 'king' and 'queen'. By manipulating vectors, relationships like family relations or national identities can be observed. Models learn to encode gender or other information in specific directions. For instance, adding the difference between 'Italy' and 'Germany' to 'Hitler' results in an embedding close to 'Mussolini'. Dot products measure alignment between vectors by multiplying corresponding components and summing the results, which is crucial for weighted sums in computations.
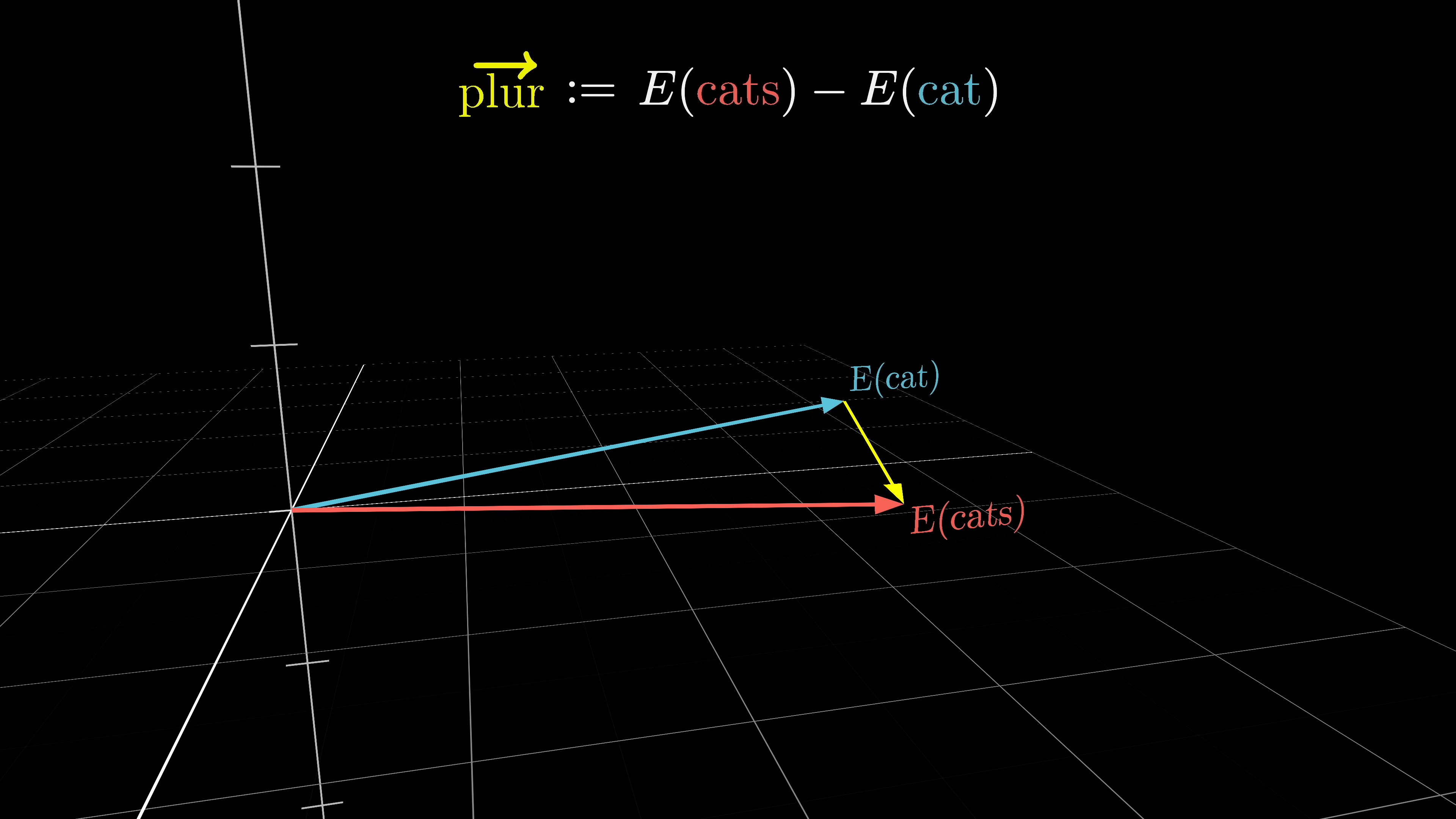
The dot product in geometry is positive when vectors point in similar directions, zero when they are perpendicular, and negative when they point in opposite directions. In an example involving embeddings of words, such as cats and cat, the hypothesis is that the vector representing the difference between cats and cat may indicate a plurality direction in the space. By computing dot products with singular and plural nouns, it is observed that plural nouns consistently yield higher values, suggesting alignment with the plurality direction.
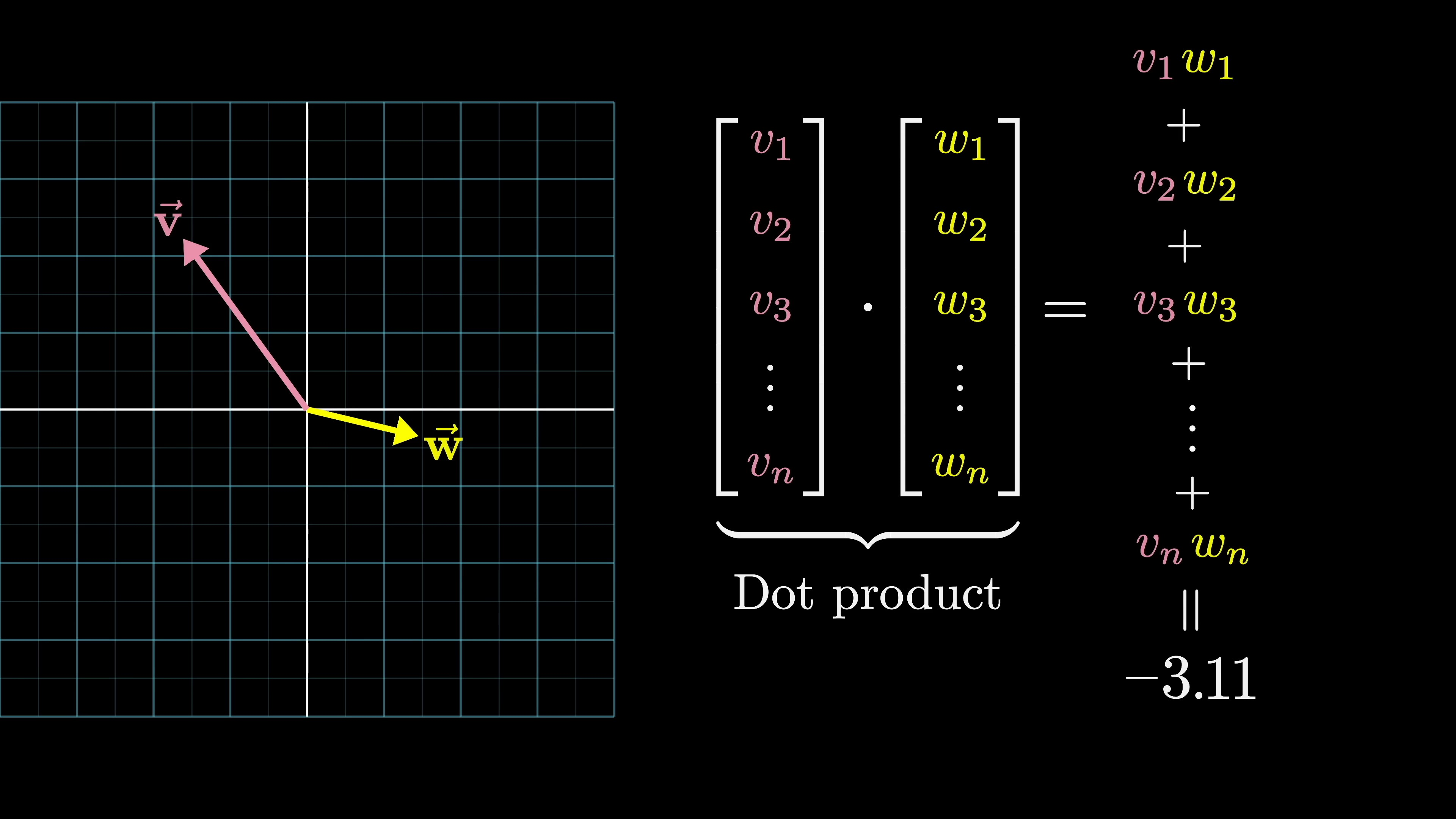
The dot product of word embeddings in a model can indicate the plural form of a word based on the increasing values it produces. The embedding matrix, which determines how words are represented, is the initial set of weights in the model. In the case of GPT-3, the vocabulary size is 50,257 tokens, not words, and the embedding dimension is 12,288.

Vectors in Transformer Embedding Space | 0:18:00-0:24:00
https://youtu.be/wjZofJX0v4M?t=1080

Consider your own understanding of a given word. The meaning of that word is heavily influenced by its context, sometimes even from a considerable distance away. Therefore, when constructing a model capable of predicting the next word, the objective should be to enable it to incorporate context optimally.
To clarify, in the initial step when creating an array of vectors based on input text, each one of them simply plucks out of the embedding matrix. Hence, each one initially can only encode the meaning of a single word, without any input from its surroundings. However, the primary goal of the network through which it flows should be to allow each of these vectors to absorb meanings that are considerably more rich and specific than what individual words could express.

Please note that the network can only process a fixed number of vectors at a time - its context size. For GPT-3, it was trained with a context size of 2048, causing the data flowing through the network to always appear as an array of 2048 columns, with each column having 12,000 dimensions. This context size limit is what determines the amount of text the transformer can incorporate when predicting the next word. Consequently, protracted conversations with certain chatbots, like early versions of ChatGPT, often gave users the sense of the bot losing the thread of conversation if continued for an extended period.

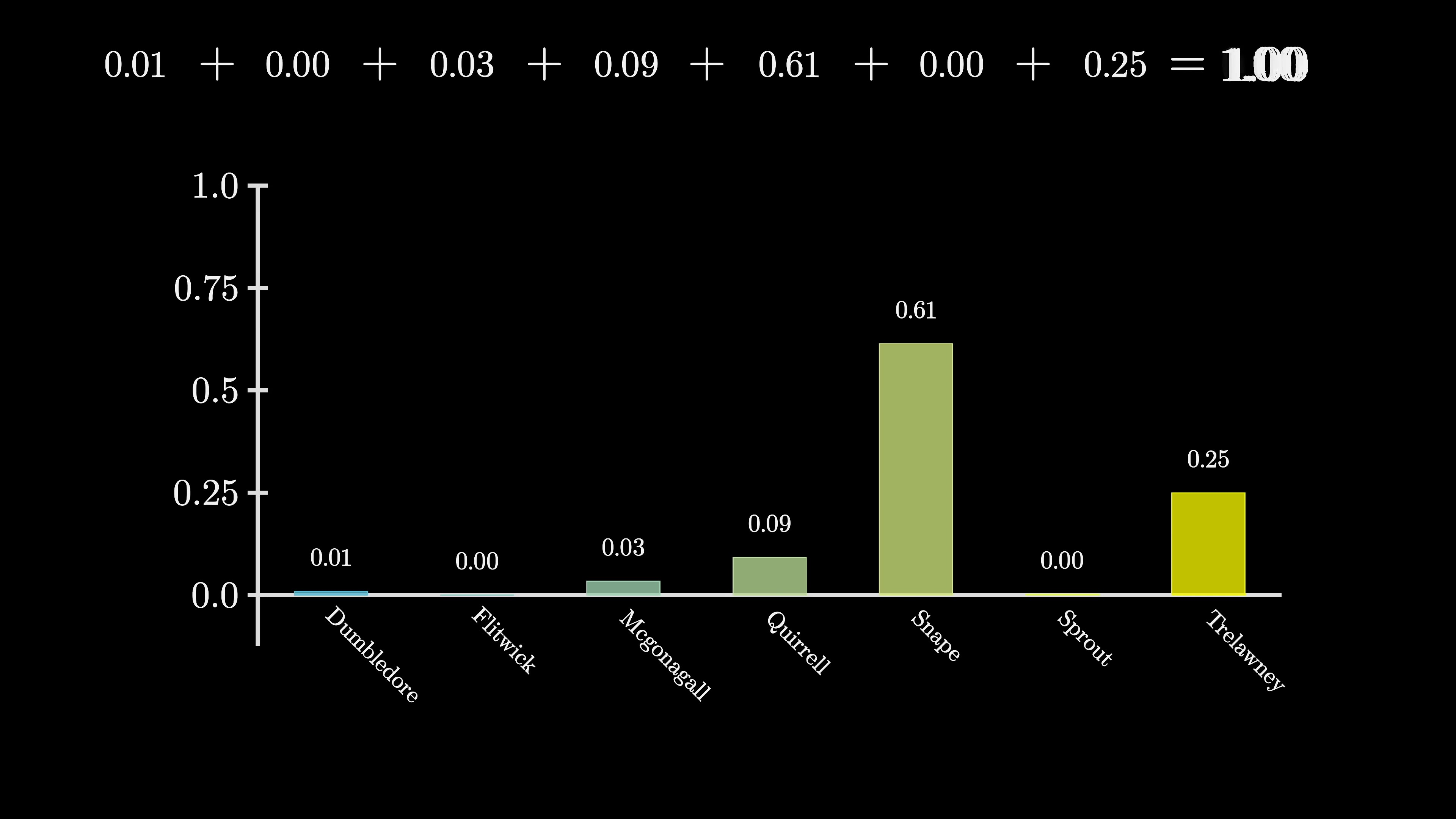
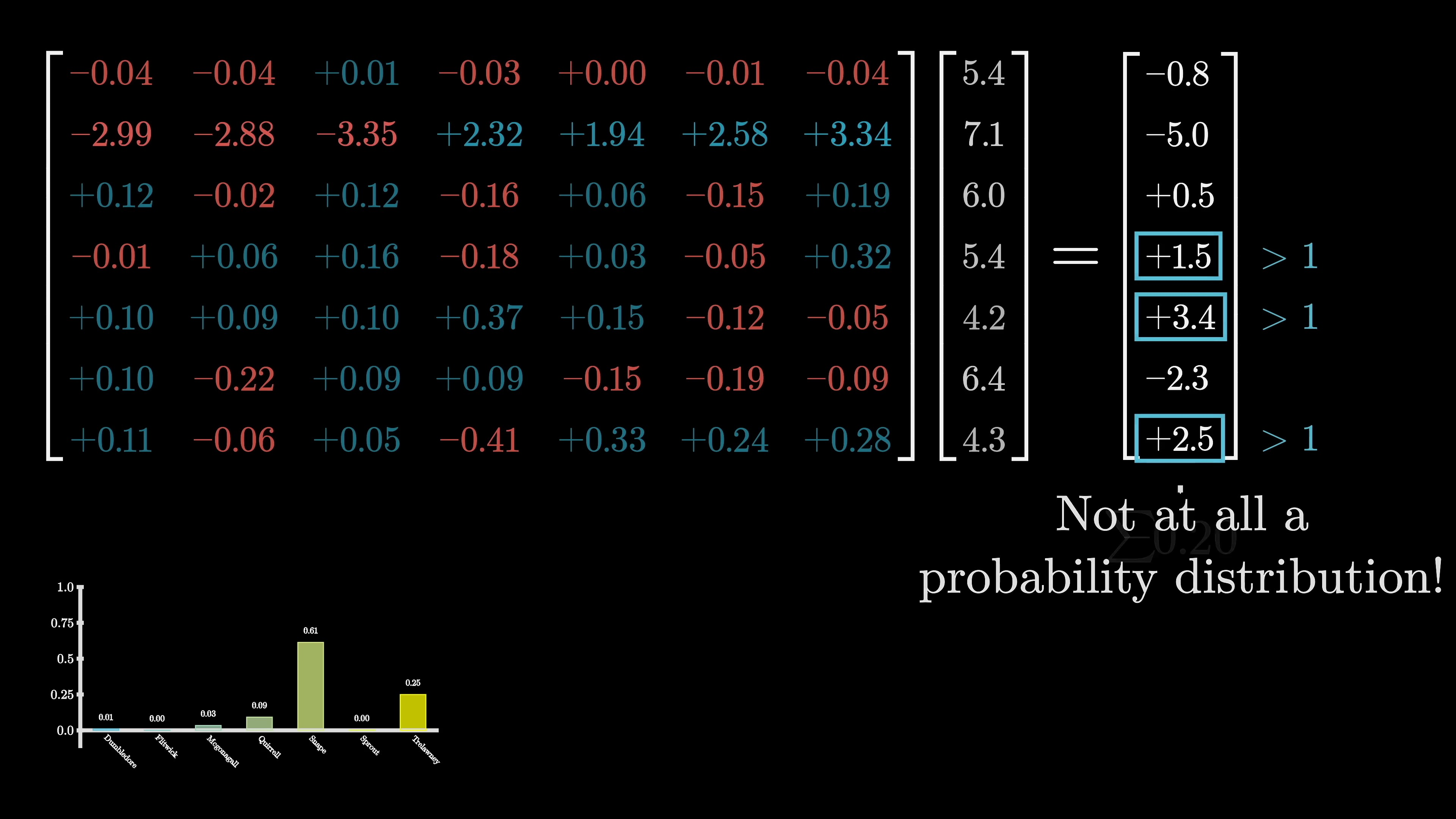
There are deeper insights to be discussed around attention, but first, let's discuss what happens at the end. Remember, the desired output is a probability distribution for all potential succeeding tokens. For instance, if the very last word is 'professor', and the context includes words like 'Harry Potter', and immediately preceding, we see 'least favorite teacher', then a well-trained network that has accumulated knowledge of Harry Potter would probably assign a high number to the word 'Snape'. This process involves two distinctive steps.
The first one is to use another matrix that maps the very last vector in that context to a list of 50,000 values, one for each token in the vocabulary. There is a function that then normalizes this into a probability distribution, known as softmax. This function will be delved into more shortly. However, it might seem off to only use this last embedding to make a prediction when, in reality, there are thousands of other vectors in that final layer, each with their own context-rich meanings.
The decision to only use the last embedding is primarily due to the training process's efficiency; it turns out to be more resource-efficient if every vector in the final layer is used to predict the word that would immediately follow it. Although more is to be said about training later on, it's important to highlight this point at this juncture. This matrix, referred to as the unembedding matrix, is labeled w-u. Like all the weight matrices observed, its entries initiate at random but are learned during the training process.
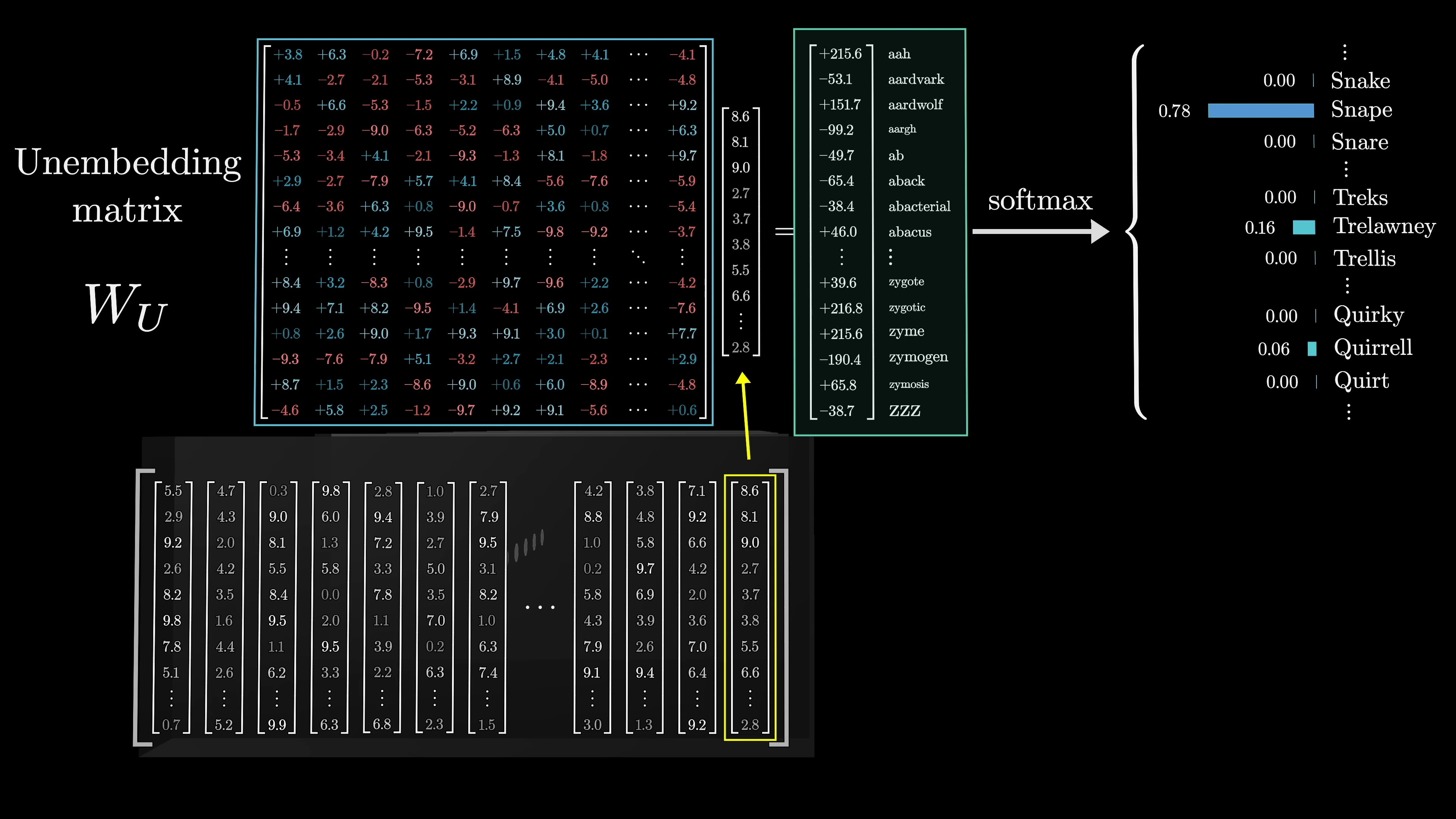
This unembedding matrix has one row for each word in the vocabulary, with each row containing the same number of elements as the embedding dimension. Its structure is very similar to the embedding matrix, just with the order swapped, so it adds another element to the network. Consequently, our tally is slightly over a billion, a small but not entirely inconsequential fraction of the 175 billion we'll ultimately total.
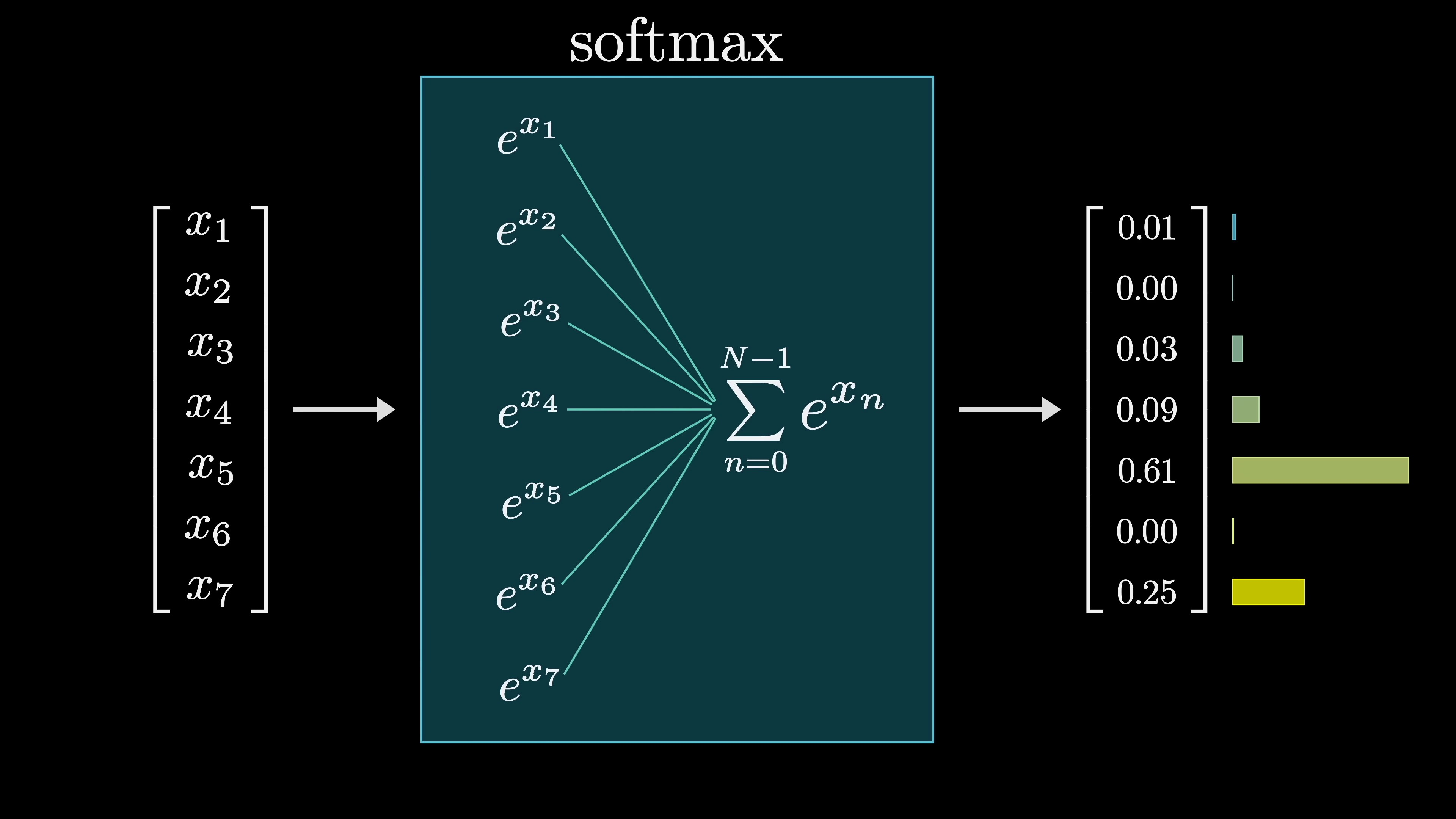
As the final mini-lesson for this chapter, let's discuss the softmax function in more depth, as it will reappear in our investigation into attention blocks. The primary idea is that if you want a sequence of numbers to act as a probability distribution (say a distribution over all possible next words), each value must range between 0 and 1, and all of them need to total 1. However, if you're playing the deep learning game where all your manipulations look like matrix vector multiplications, the outputs you get by default are unlikely to abide by these rules. The values often end up negative or much larger than 1, and they almost certainly won't total 1. The softmax function is the standard method of converting an arbitrary list of numbers into a valid distribution.

The softmax function transforms a list of numbers into a probability distribution, where larger values approach 1 and smaller values get closer to 0. The process involves raising e to the power of each number, summing the results, and dividing each term by the sum to normalize the values, ensuring that the distribution totals 1. This function allows for the dominating input to have significant impacts while still affording weight to other large values. By adjusting the 'temperature' parameter, the distribution can be modified to introduce variability and fun to the output, akin to the role of temperature in thermodynamics equations.
You assign more weight to the lower values, which results in a more uniform distribution. If t is smaller, the larger values will dominate more aggressively. At the extreme, setting t equal to 0 allocates all the weight to the maximum value. For instance, I'll have GPT-3 generate a story with the seed text, "Once upon a time there was a", but I'll use different temperatures in each case. A temperature of 0 means it always selects the most predictable word, resulting in a trite Goldilocks derivative. A higher temperature allows it to choose less probable words, but this comes with a risk. In this instance, the story starts out somewhat more originally, about a young web artist from South Korea, but it quickly descends into nonsense. Technically, the API doesn't allow you to choose a temperature greater than 2. There's no mathematical rationale for this. It's merely an arbitrary limit imposed, presumably, to prevent their tool from being seen generating excessively nonsensical content.

Regarding how this animation works, I take the 20 most probable next tokens generated by GPT-3, which seems to be the maximum they'll provide, and then I adjust the probabilities based on an exponent of 1 fifth. As another piece of jargon, in the same way we refer to the components of this function's output as probabilities, people often call the inputs logits. So for instance, when you input some text, you have all these word embeddings flowing through the network, and when you execute this final multiplication with the unembedding matrix, machine learning practitioners would refer to the components in that raw, unnormalized output as the logits for the next word prediction.
A significant goal of this chapter was to provide a foundation for understanding the attention mechanism, in a Karate Kid, wax on-wax off style. If you grasp word embeddings, softmax, how dot products measure similarity, and the basic premise that most calculations must resemble matrix multiplication with matrices filled with tunable parameters, then understanding the attention mechanism, this fundamental part of the modern AI boom, should be somewhat straight forward. I will discuss this further in the next chapter.
